Digital Eyeballs; Using Optical Character Recognition on Video Games
eh-dub AUG 29, 2021
Given the proliferation of e-sports and Twitch streamers, I wonder if it would ever be useful to watch video games really fast. Like 12 hours in 12 seconds fast.
Let's Watch People Die
Call of Duty Warzone is one of the most popular games in the contemporary competitive scene. To win, you must kill. How might we watch every murder really fast?
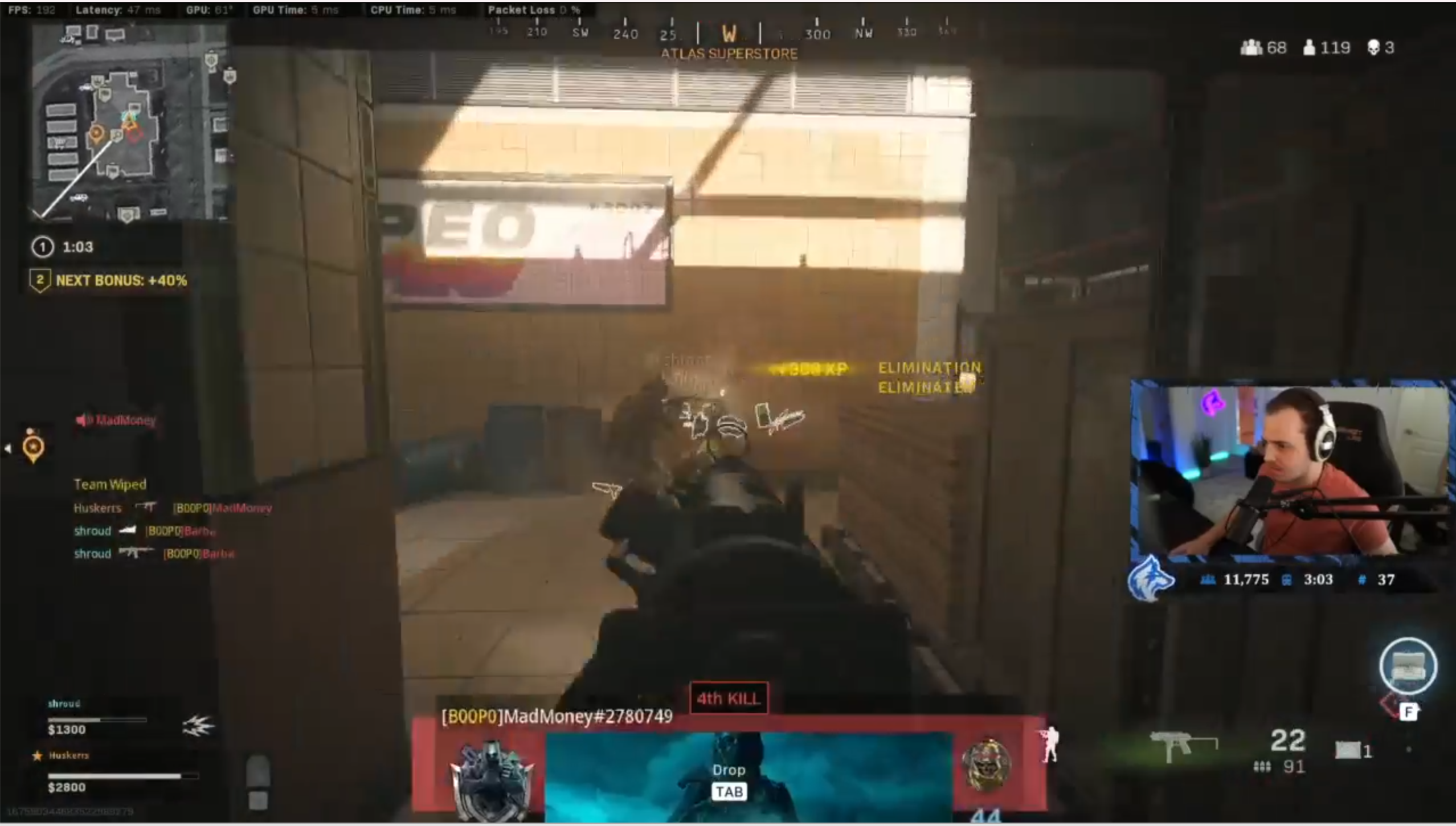
Here we see Twitch Streamer HusKers finishing off an opponent. At the top-right of the screen is a kill counter. If we can read that number then we can extract every kill that HusKers makes. Here's a scaled up view of that kill counter just before HusKerrs makes that third kill.

Recognizing numbers is Machine Learning 101. Are we at a bar on a Friday night? 'cuz we about to get dem digits.
Step one: determine a bounding box for the region of interest
My preferred method is to overlay a grid and count the boxes. Here's a working example.
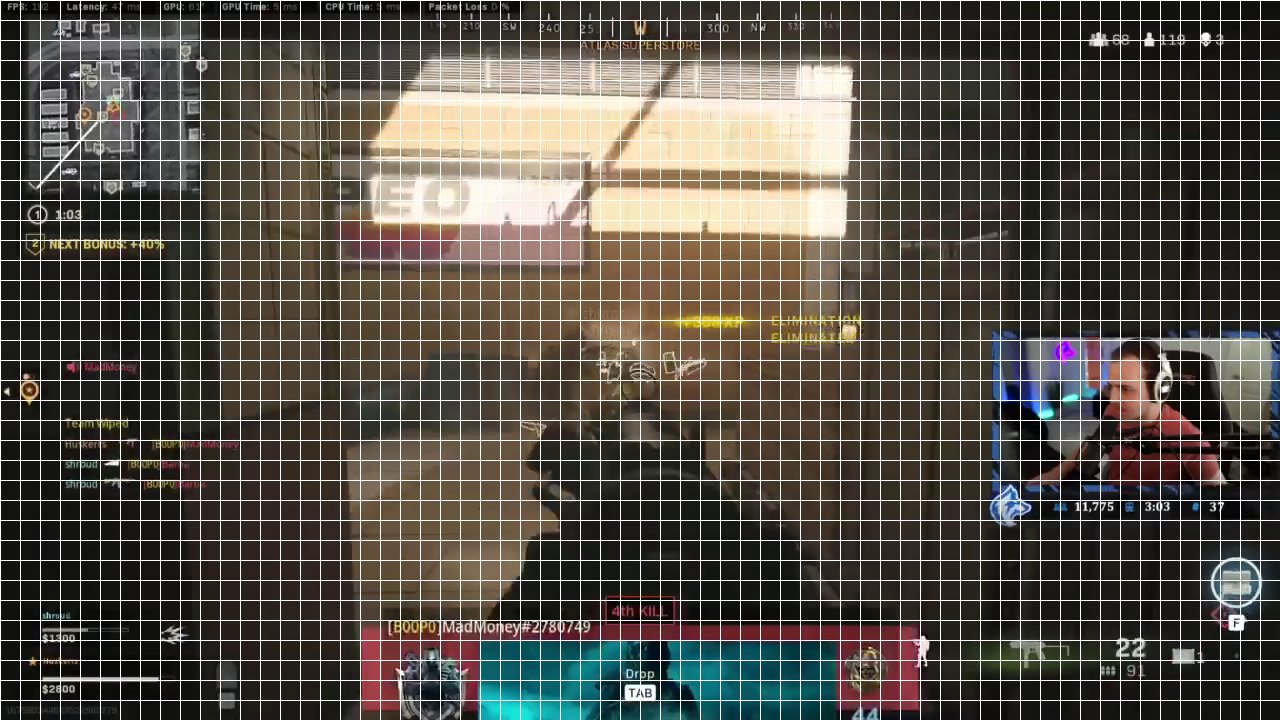
These boxes are 20 pixels by 20 pixels. The source image is 1280x720 (i.e. 720p). Counting the squares we see that the digits are contained in the space (1212,30,1247,50). I did not get these numbers from the grid alone. The grid provides a starting point and after a few iterations you will discover a tight crop. The extra space is for double-digit numbers.
Step two: use bounding box to crop region of interest from video frames
PyAV is not the most inuitive library for video processing, but it is by far the fastest Python wrapper for FFmpeg that I've used. Here is a live demo of how to use it to crop out the region of interest from the frames of a video.
Step three: configure a digital eyeball to perceive the digits
Tesseract is an open source "optical character recognizer". I think "digital eyeball" is a more intuitive name. I do not yet know how to build a REPL that runs Tesseract so here is a GitHub repo you can clone. Tesseract is invoked in the run_ocr.sh script. The command is presented on its own below:
tesseract imgs.txt results --dpi 70 --psm 7 -c tessedit_char_whitelist=0123456789 tsv
imgs.txtis a newline-separated-list of image filenames for tesseract to process.resultsis the name of the results file--dpi 70tells tesseract how many dots per inch the images are. DPI is relevant only for scanned images, but tesseract complains if you don't set this argument. 70 is tesseract's default when a DPI is not provided.--psm 7refers to the "page segmentation method" i.e. how is the text laid out on the image. 7 is "Treat the image as a single text line." Read more here.-c tessedit_char_whitelist=0123456789defines the character set that can be recognized.tsvreport results as tab-seperated values
The results reporting is the least user-friendly aspect of tesseract. At least in this example, images where characters are recognized have 5 result lines and images where characters are not recognized have 1 result line. Of the 5 result lines, just one contains the actual character recognized. I chose tsv for this demo because it at least includes no-recognition results. The default txt results reporting includes only recognitions so it is impossible to know which recognitions correspond to which inputs.
Putting it all together is the hard part
I have demonstrated transformations from video to cropped frames to recognized digits. In a future post I will demonstrate how to program against this event stream to pull out events of interest.